
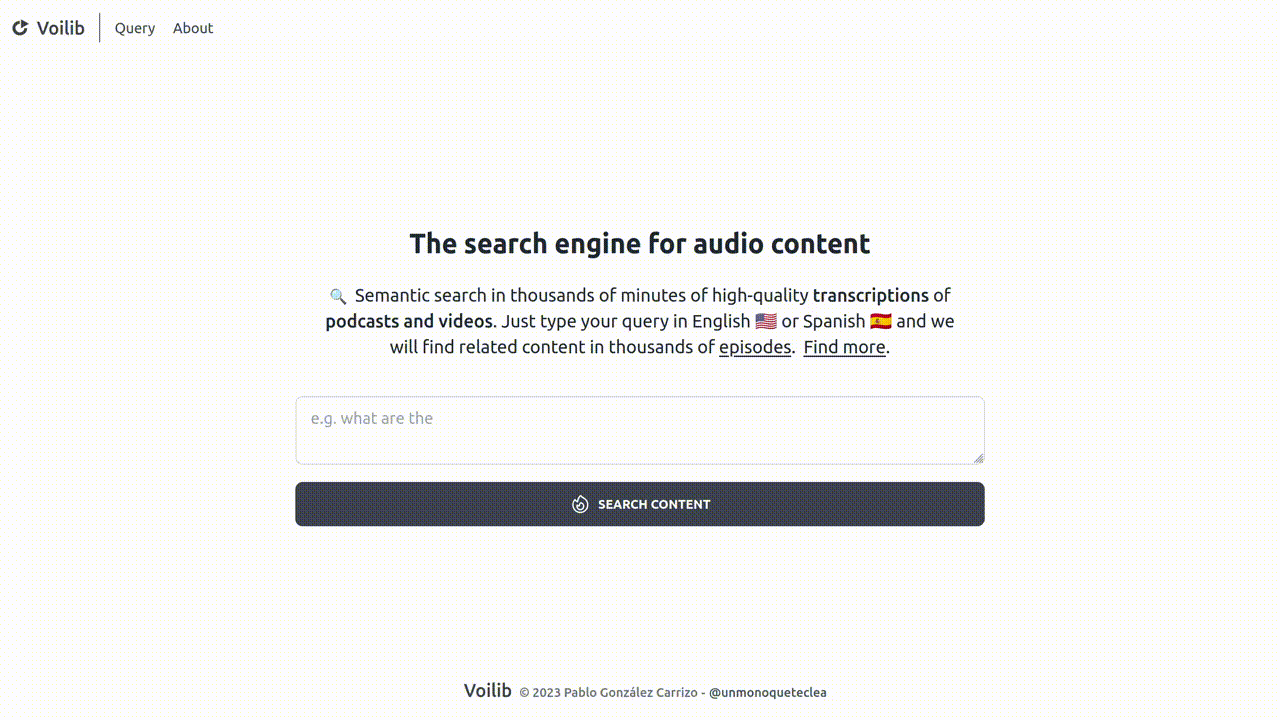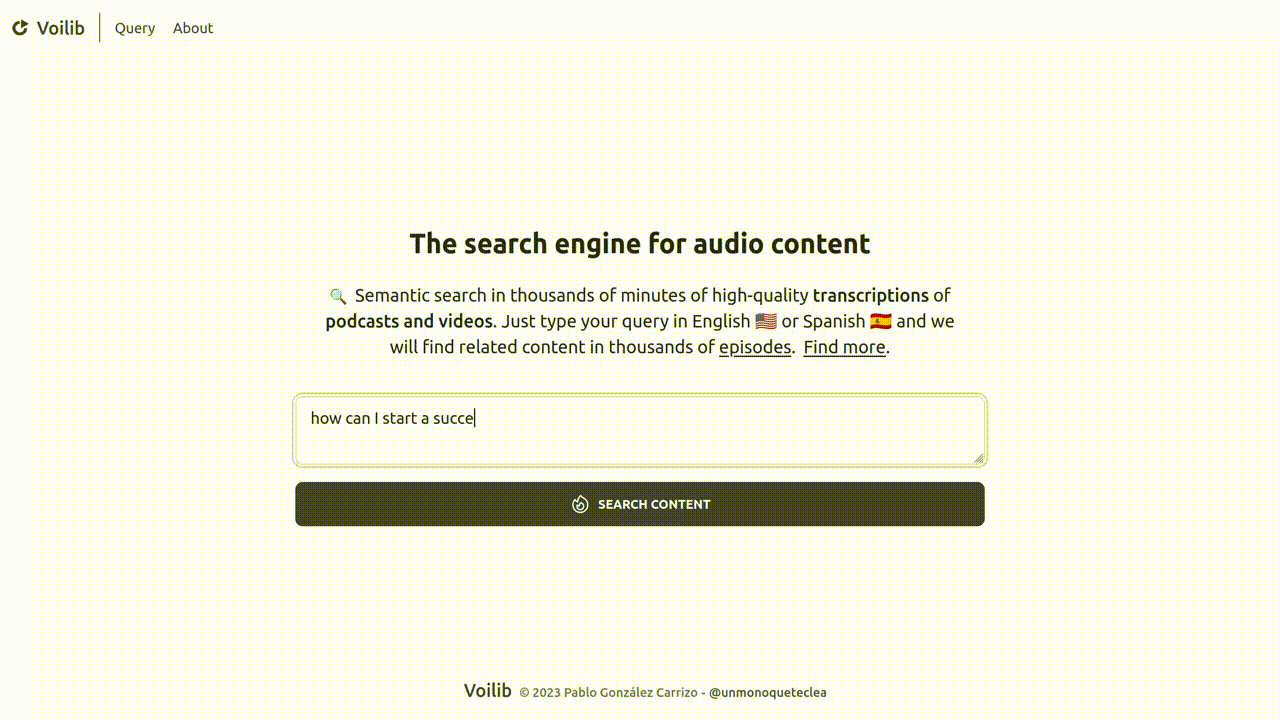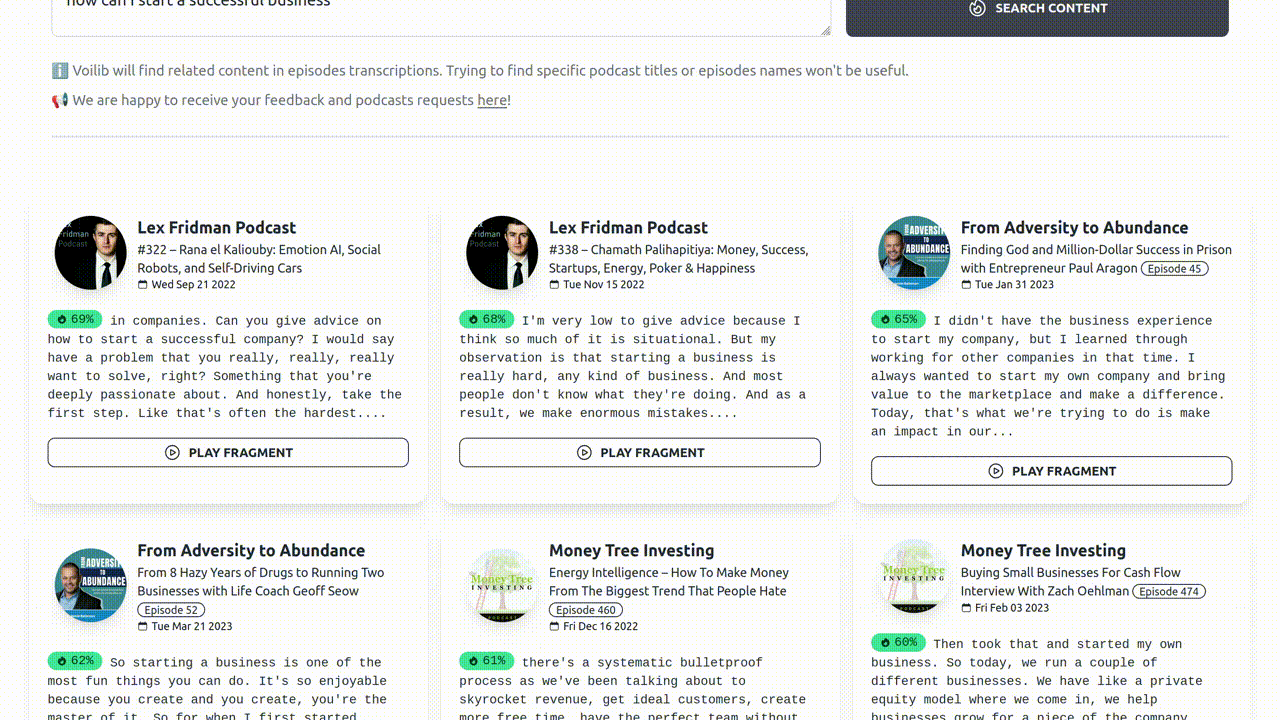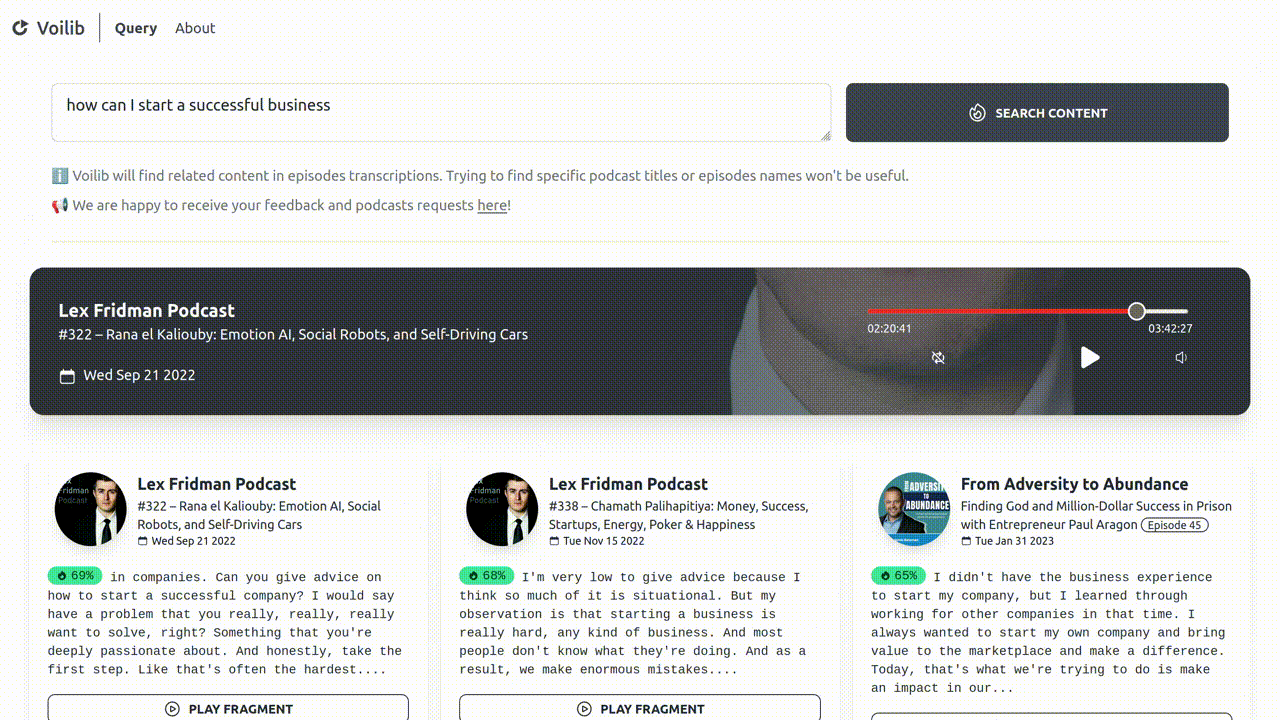
The technology behind Voilib
Each week, Voilib diligently collects and transcribes hundreds of podcast episodes. These valuable transcripts undergo a meticulous indexing process, enabling a sophisticated semantic search capability. As a result, our users can effortlessly execute intelligent queries, pinpointing precisely the most relevant fragments of podcast episodes.
I launched Voilib in December 2022 and, some months later, I decided to embrace openness by making Voilib Open Source. This alowed everyone to create their own instances, transcribe, and index their cherished podcasts. You'll find it easily accessible on both Github and Gitlab. As promised, let me take you on a fascinating journey into the captivating technology behind it.
Essentially, Voilib's work can be divided into four main tasks: collecting new episodes, transcribing them, indexing all the content, and querying the vector database to find relevant fragments.
🌐 Collect (new episodes)
Almost all public podcasts have an associated RSS feed that contains
metadata about every episode, including a link to the audio file. As
an example, this is the feed from the Ted Talks Daily podcast.
Voilib collects and stores metadata from the list of podcasts feeds
manually configured by the application admin. For each episode, it
stores in a SQLite database things such as the title, the description,
the language or the duration.
When I want to check if new episodes were published, I just need to run this in a command line (although I have a cron job configured to run it twice a day):
voilib-episodes --update
If you want to dig into the code, check feed.py and crawler.py modules.
🗨️ Transcript (episodes audios)
The podcast episodes are transcribed using Whisper, an Open Source
Speech Recognition Model developed by OpenAI. Voilib effectively
leverages Whisper, utilizing the whisper-jax library. This
particular implementation of Whisper boasts exceptional efficiency,
showcasing speeds up to 70 times faster than comparable alternatives.
However, most whisper-jax optimizations are predominantly GPU-focused (that Voilib is not using yet), I must admit that I have not observed significant improvements in CPU performance when compared to the official implementation. Nevertheless, the accuracy of this model is nothing short of remarkable, even for the small version with "just" 39M parameters. It is truly astonishing to think that a few years ago, having an Open Source Speech Recognition model as swift and accurate as this one would have been deemed nearly implausible.
When I want to transcribe the new episodes from the last 3 days, I just need to run this (I also have a cron job configured to run it):
voilib-episodes --transcribe-days 3
For curious minds, you can check transcription.py module.
📇 Index (episodes trancriptions)
The process of generating episode transcripts involves breaking them
down into fragments, each comprising approximately 40 words. Voilib
employs the sentence-transformers Python library to calculate the
embedding of each 40-words fragment, effectively transforming it into
a 384-dimensional vector of floating point numbers.
To shed light on the concept of embeddings, they can be defined as lower-dimensional spaces that allow for the translation of high-dimensional vectors. The goal of embeddings is to capture semantic similarity, ensuring that inputs with similar meanings are placed closer together in the embedding space.
The sentence-transformers library stands out as the optimal choice for creating text embeddings. This is the description from their website:
You can use this framework to compute sentence / text embeddings for more than 100 languages. These embeddings can then be compared e.g. with cosine-similarity to find sentences with a similar meaning. This can be useful for semantic textual similar, semantic search, or paraphrase mining.
The framework is based on PyTorch and Transformers and offers a large collection of pre-trained models tuned for various tasks. Further, it is easy to fine-tune your own models.
The model Voilib is using to calculate the embeddings is
multi-qa-MiniLM-L6-cos-v1. This model have been specifically trained
for Semantic Search with 215M question-answer pairs from various
sources and domains.
You can find the code for Voilib's embedding calculation in the embedding.py module.
Those calculated vectors are then stored in a vector database, one of the main components of the system. More on this in the next section.
🔍 Query (embeddings)
Each episode's embeddings are meticulously preserved within a vector database. In recent months, we have witnessed a surge in new technologies specifically designed for storing embeddings. These innovative solutions empower us to efficiently store embeddings and seamlessly query them using cutting-edge Approximate Nearest Neighbor search algorithms.
During the initial stages, Voilib relied on Meta's FAISS library for embedding storage. However, to enhance the system and include additional metadata for each embedding (that can be also used to filter queries), I decided to migrate to qdrant, a higher-level solution. With qdrant, we achieve the ability to incorporate supplementary metadata while seamlessly managing embeddings. As part of this evolution, Voilib now operates its own instance of the qdrant server, further ensuring data autonomy and control.
For every user prompt, Voilib performs a swift calculation of the corresponding embedding and efficiently queries the vector database. This process enables the system to swiftly identify and return the most relevant results, ensuring a seamless and satisfying user experience.
Of course, there is another command to calculate and store embeddings from all pending episodes:
voilib-episodes --store
More, in the vector.py module.
Happy to receive your feedback
Please feel free to reach out to me at unmonoqueteclea@gmail.com with
your thoughts, suggestions, or any inquiries.
I am eager to know which podcasts you would like to see available on Voilib. Additionally, if there are any specific features that you believe would enhance your user experience and make your life easier, please do not hesitate to share them with me. It's a fantastic opportunity to contribute to the open-source community.
If you have been considering hosting your own instance, I would be thrilled to support and guide you through the process.
I look forward to hearing from you!